
 photoshop cs6 破解版
photoshop cs6 破解版
 嗨格式抠图大师 官方版 v1.4.151.0
嗨格式抠图大师 官方版 v1.4.151.0
 coreldraw 9 简体中文版
coreldraw 9 简体中文版
 Sketchup2020 最新版
Sketchup2020 最新版
 风云抠图 官方版 v2.0.0.1
风云抠图 官方版 v2.0.0.1
 Exposure2021 官方版
Exposure2021 官方版

Tesseract OCR 是一款由惠普实验室开发、现由谷歌维护的开源光学字符识别(OCR)引擎,它能够将图像中的印刷体和手写体文字转换为可编辑和可搜索的文本格式。该软件支持超过 100 种语言,包括中文、英文、日文等,并具备强大的识别能力和自定义训练功能,用户可通过提供样例数据训练模型,提高特定文档的识别准确率。此外,Tesseract OCR 还提供丰富的 API 支持,兼容 C++、Python 等多种编程语言,方便开发者集成到各类应用中。
软件亮点
免费开源:无需支付费用,适合个人和企业使用。
高准确性:对于印刷体文本的识别率较高。
多语言支持:支持超过 100 种语言,满足国际化需求。
可定制性强:用户可以根据需求训练自定义模型。
软件特色
开源与可定制性:
Tesseract OCR 是开源软件,用户可以根据需求修改代码或训练自定义模型。
提供训练工具,允许用户根据特定需求训练自定义模型,以提高对特定类型或格式文本的识别准确率。
跨平台兼容性:
支持 Windows、Mac OS 和 Linux 等多种操作系统。
提供命令行工具,用户可以通过简单的命令行输入执行 OCR 任务。
编程语言接口:
提供多种编程语言的 API 接口,如 C++、Python、Java 等,方便开发者将 OCR 功能集成到各种应用程序中。
软件功能
文本识别与转换:
Tesseract OCR 能够识别图片中的文字,并将其转换为可编辑的文本格式(如 TXT、PDF 等)。
支持多种图像文件格式,包括 JPEG、PNG、TIFF 等。
多语言支持:
支持超过 100 种语言,包括英文、中文、德文、法文等。
用户可以通过下载相应的语言包来扩展识别语言。
高准确性:
对于印刷体文本的识别率高达 95% 以上,在同类产品中处于领先地位。
采用图像处理、特征提取和机器学习技术,通过训练好的模型识别字符,并结合上下文和语言模型提高识别准确性。
常见问题
识别率低
问题描述:
识别结果与原文差异较大,尤其在中文、手写体或复杂排版场景中表现明显。
解决方案:
图像预处理:调整分辨率至300DPI以上,使用Photoshop或ImageMagick增加行距、去除噪声、校正倾斜。
参数优化:
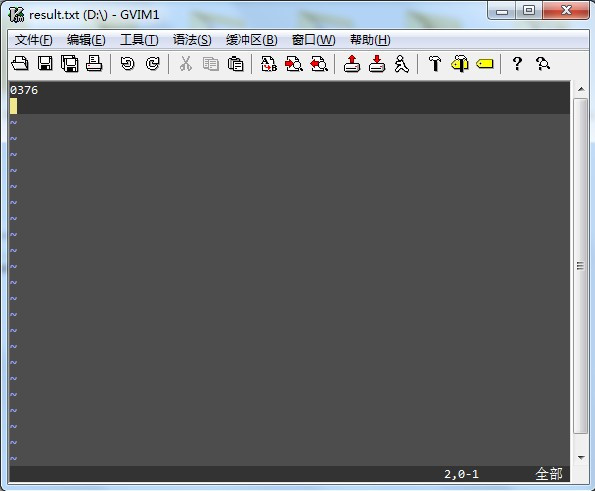
指定语言:-l chi_sim(简体中文)或-l eng(英文)。
调整页面分割模式:--psm 6(单行文本)或--psm 3(全页文档)。
启用LSTM引擎:--oem 1(推荐模式)。
自定义训练:收集目标字体样本,生成标注文件(.box),训练语言模型(.traineddata),并加载至Tesseract。



































